켄텍 이석주 교수 연구팀, 경량 프롬프트 학습 기술 개발로 인공지능 공간 이해 한계 돌파
한국에너지공대(KENTECH, 총장직무대행 박진호)는 이석주 교수 연구팀이 비전-언어 모델(Vision Language Model, VLM)의 3차원 공간적 추론을 가능하게 하는 경량 프롬프트 학습 기술을 개발했다고 1일 밝혔다. 연구진은 이 기술을 단일 카메라 기반의 깊이 추정 기법에 응용해 인공지능의 공간 이해 능력을 크게 향상시켰다.
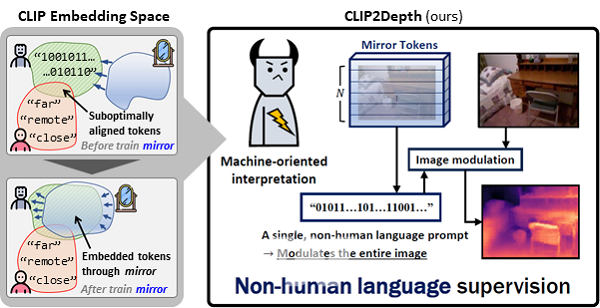
멀티모달 및 비전-언어 모델 CLIP은 이미지와 텍스트를 동시에 이해하는 인공지능으로, 비전과 자연어 처리 융합 분야에서 널리 활용된다. 예를 들어 ‘고양이’라는 단어를 보여주면 수많은 사진 속에서 고양이를 찾아내는 방식이다. 하지만 거리와 깊이 인식과 같은 기하학적 공간 이해 영역에는 한계가 있었다.
연구팀은 이를 극복하기 위해 사람이 쓰는 언어 대신, 기계가 이해하기 최적화된 새로운 표현 방식인 비인간 언어 프롬프트를 도입했다. 이를 통해 카메라에 찍힌 사진이나 영상만으로도 물체의 깊이를 정밀하게 파악할 수 있도록 했다.
실험 결과, 이번 기술은 약 110만 개 학습 파라미터만으로도 기존의 대형 모델들(3억 개 이상)과 견줄 만한 성능을 보였다. 필요한 파라미터 수가 300분의 1 수준으로 줄었지만, 성능 저하 없이 효과적인 학습이 가능했다. 이석주 교수는 “자율주행, 로봇 비전, 증강현실 등 경량화가 필수적인 다양한 공간 컴퓨팅 분야에 활용 가능한 핵심 원천기술로 자리매김할 것”이라고 강조했다.
이번 연구는 산업통상자원부, 한국연구재단, 한국천문연구원의 지원을 받아 수행됐으며, 컴퓨터 비전 및 기계 학습 분야의 세계적 권위 학술지 Pattern Recognition (Elsevier, SCIE Q1, IF=7.6)에 9월 26일 온라인 게재됐다.
- 켄텍-한전KDN-디지털ESG얼라이언스, 'ESG 디지털 플랫폼' 공동 구축
- 한전KDN-켄텍-i-DEA, '글로벌 환경규제 대응' 사업 발굴 및 활성화 협력 약속
- 켄텍, '패밀리기업 플랫폼 출범'... 117개 기업과 에너지 산업 동반성장
- 무결점 전력공급 APEC 성공 뒷받침 한다... 한전, 전력확보 상황실과 특별기동대 본격 가동
- 한전KPS, 민간 거래회사 맞춤형 '청렴포켓북' 발간
- 한전KDN, 노사협의 통한 강화된 방염작업복 지급으로 현장 안전에 만전 기해
- 한전, 말레이시아 전력공사와 신사업·신기술 협력 강화
- 한전, 추석 명절 앞두고 따뜻한 온정 전해
- “보행자를 표지판으로? 자율주행차 맹점 찾아냈다” GIST, 자율주행차 인식 시스템 취약점 드러내는 새 알고리즘 개발… 안전성 개선 활용 기대
- 콘진원, 콘텐츠산업 인공지능 활용 동향 결과 발표
- [내일날씨]2일 전국적으로 흐리고 비...추석연휴 전 마지막 출근, 쌀쌀하지만 마음은 따뜻
- 국립순천대학교, 교직원 대상 ‘대학 통합 추진 공청회’ 개최